Mapping COVID19: a technology overview
/Hello everyone, I hope you are all healthy, safe, sane, and if possible, being productive.
Here I provide a summary of some of the mapping technology that has been used in the past few weeks to understand the COVID-19 pandemic. This is not exhaustive! I pick three areas that I am personally focusing on currently: map-based data dashboards, disease projections, and social distancing scorecards. I look at where the data comes from and how the sites are built. More will come on the use of remote sensing and earth observation data in support of COVID-19 monitoring, response or recovery, and some of the cool genome evolution and pandemic spread mapping work going on.
COVID-19 map-based data dashboards. You have seen these: lovely dashboards displaying interactive maps, charts, and graphs that are updated daily. They tell an important story well. They usually have multiple panels, with the map being the center of attention, and then additional panels of data in graph or tabular form. There are many many data dashboards out there. My two favorites are the Johns Hopkins site, and the NYTimes coronavirus outbreak hub.


Where do these sites get their data?
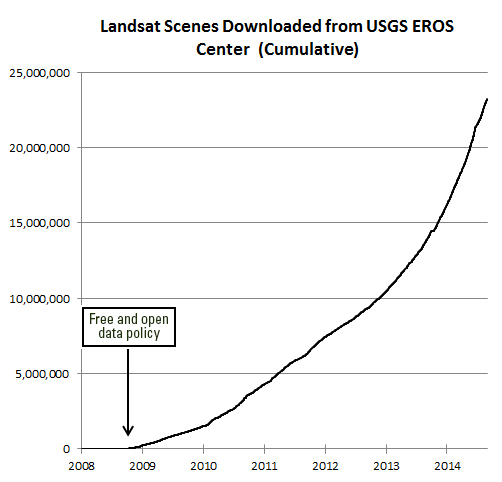
Most of these sites are using data from similar sources. They use data on number of cases, deaths, and recoveries per day. Most sites credit WHO, US CDC (Centers for Disease Control and Prevention), ECDC (European Centre for Disease Prevention and Control), Chinese Center for Disease Control and Prevention (CCDC), and other sources. Finding the data is not always straightforward. An interesting article came out in the NYTimes about their mapping efforts in California, and why the state is such a challenging case. They describe how “each county reports data a little differently. Some sites offer detailed data dashboards, such as Santa Clara and Sonoma counties. Other county health departments, like Kern County, put those data in images or PDF pages, which can be harder to extract data from, and some counties publish data in tabular form”. Alameda County, where I live, reports positive cases and deaths each day, but they exclude the city of Berkeley (where I live), so the NYTimes team has to scrape the county and city reports and then combine the data.
Some of the sites turn around and release their curated data to us to use. JH does this (GitHub), as does NYTimes (article, GitHub). This is pretty important. Both of these data sources (JH & NYTimes) have led to dozens more innovative uses. See the Social Distancing Scorecard discussed below, and these follow-ons from the NYTimes data: https://chartingcovid.com/, and https://covid19usmap.com/.
However… all these dashboards are starting with simple data: number of patients, number of deaths, and sometimes number recovered. Some dashboards use these initial numbers to calculate additional figures such as new cases, growth factor, and doubling time, for example. All of these data are summarized by some spatial aggregation to make them non-identifiable, and more easily visualized. In the US, the spatial aggregation is usually by county.
How do these sites create data dashboards?
The summarized data by county or country can be visualized in mapped form on a website via web services. These bits of code allow users to use and display data from different sources in mapped form without having to download, host, or process them. In short, any data with a geographic location can be linked to an existing web basemap and published to a website; charts and tables are also done this way. The technology has undergone a revolution in the last five years, making this very doable. Many of the dashboards out there use ESRI technology to do this. They use ArcGIS Online, which is a powerful web stack that quite easily creates mapping and charting dashboards. The Johns Hopkins site uses ArcGIS Online, the WHO does too. There are over 250 sites in the US alone that use ArcGIS Online for mapping data related to COVID-19. Other sites use open source or other software to do the same thing. The NYTimes uses an open source mapping platform called MapBox to create their custom maps. Tools like MapBox allow you to pull data from different sources, add those data by location to an online map, and customize the design to make it beautiful and informative. The NYTimes cartography is really lovely and clean, for example.
An open access peer reviewed paper just came out that describes some of these sites, and the methods behind them. Kamel Boulos and Geraghty, 2020.
COVID-19 disease projections. There are also sites that provide projections of peak cases and capacity for things like hospital beds. These are really important as they can help hospitals and health systems prepare for the surge of COVID-19 patients over the coming weeks. Here is my favorite one (I found this via Bob Watcher, @Bob_Wachter, Chair of the UCSF Dept of Medicine):
Institute for Health Metrics and Evaluation (IHME) provides a very good visualization of their statistical model forecasting COVID-19 patients and hospital utilization against capacity by state for the US over the next 4 months. The model looks at the timing of new COVID-19 patients in comparison to local hospital capacity (regular beds, ICU beds, ventilators). The model helps us to see if we are “flattening the curve” and how far off we are from the peak in cases. I’ve found this very informative and somewhat reassuring, at least for California. According to the site, we are doing a good job in California of flattening the curve, and our peak (projected to be on April 14), should still be small enough so that we have enough beds and ventilators. Still, some are saying this model is overly optimistic. And of course keep washing those hands and staying home.

Where does this site get its data?
The IHME team state that their data come from local and national governments, hospital networks like the University of Washington, the American Hospital Association, the World Health Organization, and a range of other sources.
How does the model work?
The IHME team used a statistical model that works directly with the existing death rate data. The model uses the empirically observed COVID-19 population and calculates forecasts for population death rates (with uncertainty) for deaths and for health service resource needs and compare these to available resources in the US. Their pre-print explaining the method is here.
On a related note, ESRI posted a nice webinar with Lauren Bennet (spatial stats guru and all-around-amazing person) showing how the COVID-19 Hospital Impact Model for Epidemics (CHIME) model has been integrated into ArcGIS Pro. The CHIME model is from Penn Medicine’s Predictive Healthcare Team and it takes a different approach than the IHME model above. CHIME is a SIR (susceptible-infected-recovery) model. A SIR model is an epidemiological model that estimates the probability of an individual moving from a susceptible state to an infected state, and from an infected state to a recovered state or death within a closed population. Specifically, the CHIME model provides estimates of how many people will need to be hospitalized, and of that number how many will need ICU beds and ventilators. It also factors social distancing policies and how they might impact disease spread. The incorporation of this within ArcGIS Pro looks very useful, as you can examine results in mapped form, and change how variables (such as social distancing) might change outcomes. Lauren’s blog post about this and her webinar are useful resources.
Social distancing scorecards. This site from Unicast got a lot of press recently when it published a scoreboard for how well we are social distancing under pandemic rules. It garnered a lot of press because it tells and important story well, but also, because it uses our mobile phone data (more on that later). In their initial model, social distancing = decrease in distance traveled; as in, if you are still moving around as you were before the pandemic, then you are not socially distancing. There are some problems with this assumption of course. As I look out on my street now, I see people walking, most with masks, and no one within 10 feet of another. Social distancing in action. These issues were considered, and they updated their scorecard method. Now, in addition to a reduction in distance traveled, they also include a second metric to the social distancing scoring: reduction in visits to non-essential venues. Since I last blogged about this site nearly two weeks ago, California’s score went from an A- to a C. Alameda County, where I live, went from an A to a B-. They do point out that drops in scores might be a result of their new method, so pay attention to the score and the graph. And stay tuned! Their next metric is going to be the change rate for the number of person-to-person encounters for a given area. Wow.

Where do these sites get their data?
The data on reported cases of COVID-19 is sourced from the Corona Data Scraper (for county-level data prior to March 22) and the Johns Hopkins Github Repository (for county-level data beginning March 22 and all state-level data).
The location data is gathered from mobile devices using GPS, Bluetooth, and Wi-Fi connections. They use mobile app developers and publishers, data aggregation services, and providers of location-supporting technologies. They are very clear on their privacy policy, and they do say they are open to sharing data via dataforgood@unacast.com. No doubt, this kind of use of our collective mobile device location data is a game-changer and will be debated when the pandemic is over.
How does Unicast create the dashboard?
They do something similar to the dashboard sites discussed above. They pull all the location data together from a range of sites, develop their specific metrics on movement, aggregate by county, and visualized on the web using custom web design. They use their own custom basemaps and design, keeping their cartography clean. I haven’t dug into the methods in depth yet, but I will.
Please let me know about other mapping resources out there. Stay safe and healthy. Wash those hands, stay home as much as possible, and be compassionate with your community.